선 인증과 요약 후 글을 진행합니다.
요약 : ADSP 와 빅분기 필기의 시험 범위 및 난이도는 대동소이합니다.
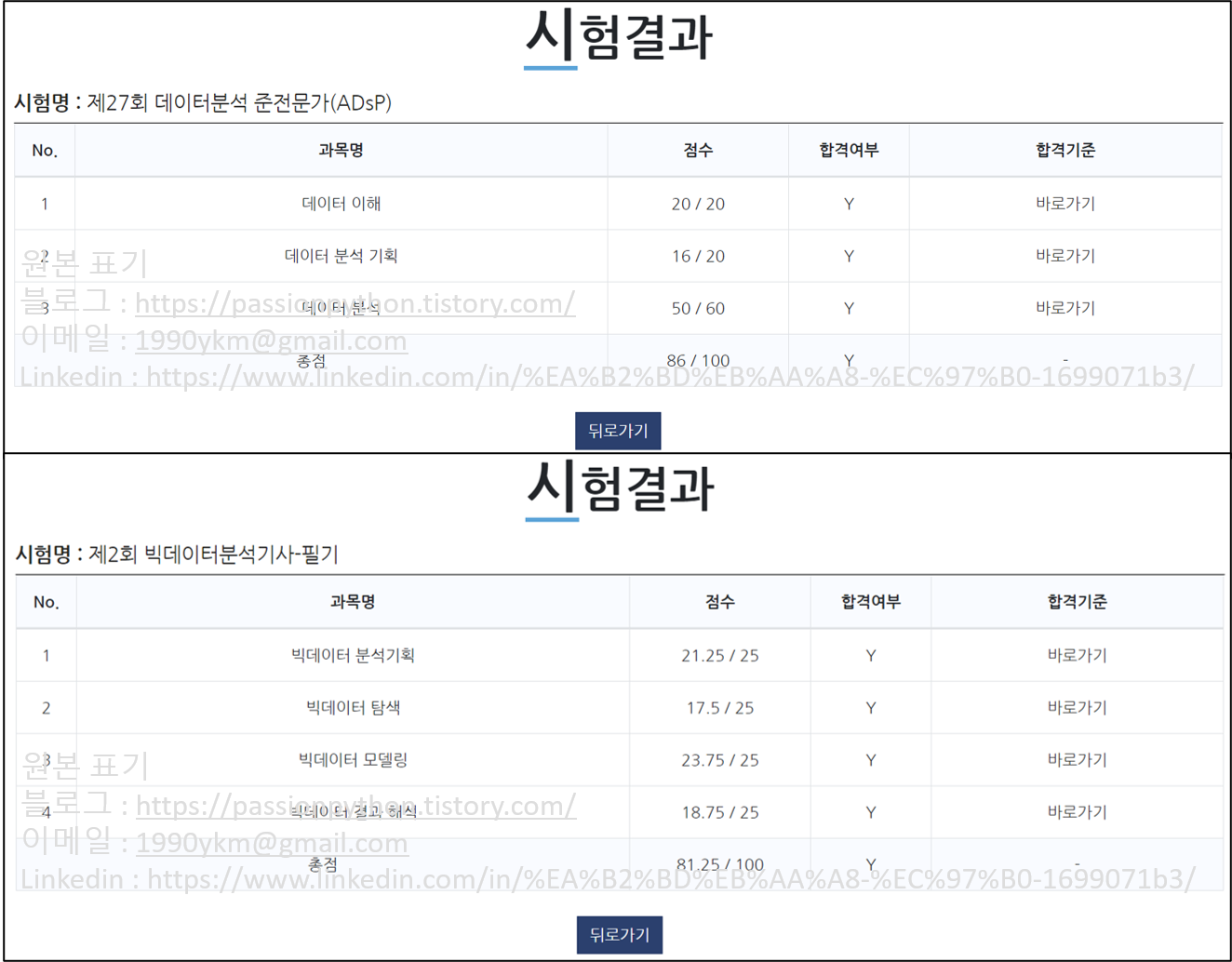
빅데이터 분석기사(이후 빅분기로 통칭) 자격이 신설되었고,
코로나로 인해 1회 시험이 취소되었으므로
사실상 이번 2회차 시험이 1회의 성격을 갖게 되었습니다.
시험은 일반적으로 수험서를 통해 준비하지만,
이번 빅분기 2회 필기시험은 최초 시험이라 기출문제가 없었기 때문에
시험 전까지 기분상 준비가 막연하고 진입장벽이 높았던 것이 사실입니다.
그러나 이번 시험 필기 합격률은 41.5%로,
체감과는 다르게 실제로는 진입장벽이 그리 높지 않았음을 보여줍니다.
출처 : cafe.naver.com/sqlpd/19899
이 숫자는 데이터 분석 분야 유사 시험인 ADSP 합격률인 40% 대와 거의 동일한데
차이점으로는 ADSP 는 기출문제 기반 유/무료 수험자료가 시중에 많이 풀려있는 상태입니다.
ADSP 는 시험 주최사에서 공식 수험도서 또한 만들어 두었기 때문에
공식 + 사설 수험자료가 체감 시험 난이도에 영향을 크게 주었고 결과로 합격률 40% 대가 나온 것입니다.
(1년에 4번 시험이 있으므로 1년 쉬엄쉬엄 4회 수행시 어지간하면 합격한다는 의미이기도 합니다.)
위 정보로 미루어보아 이번 빅분기 필기 시험의 합격률이 ADSP와 유사한 41.5% 라는 것은
1. 시험 주최사에서 제공하는 공식 수험도서가 존재하지 않았고
2. 기출문제가 없었기 때문에 사제 수험도서들은 적중률이 매우 낮았다는 것을 고려하면
3. 향후 3~5회차 이상 시험 진행시 문제은행화되어 합격률이 더 올라갈 것이라 예상합니다.
이는 주최 측에서 난이도 조절을 어떻게 이어나가느냐에 달려있기는 합니다.
그러나 빅분기가 ADSP 보다 합격률이 올라갈 것(난이도 하락)으로 예상하는데 그 근거는 다음과 같습니다.
교육 인프라가 ADSP 보다 더 활성화 될 것이라 보기 때문.
ADSP 는 민간자격이지만 빅분기는 국가(기사)자격이기 때문에 가산점 등 활용처도 더 넓습니다.
따라서 교육시장의 파이 측면으로 수요가 기존 ADSP 대비 압도적으로 많을 것으로 확신.
난이도를 올린다 하더라도 그 이상으로 자료가 풍부해지고 족집게 강의 등도 출현할 것이기 때문.
기사 자격의 특성상 난이도를 끌어올린다 해도 상승 한계지점이 명확 - 석사 수준은 X
고로, 빅분기는 향후 데이터 분석 분야에서 입문자용/엔트리급 자격으로 자리매김하지 않을까 예상합니다.
(실기시험의 경우에도 예상문제 확인결과 기존 데이터 분석 실기시험인 ADP 실기 대비 난이도가 매우 낮습니다.)
[부록]
ADSP 시험 난이도가 낮다고 주장하는 근거:
합격률 40%로 가정하고 합격할 때 까지 시험을 본다면
횟수 누적에 따른 최종합격률은 아래와 같습니다.

1년에 4회 시험일정이 있고, 매 회 시험본다면 1년 응시시 87%, 2년 응시시 98% 확률로 합격이 가능하기 때문입니다.
(ADSP 시험은 전업으로 수험준비를 하지 않고, 빠르면 공부시간 2주 안에 합격했다는 수기가 올라오기도 합니다.)
위 결과를 내는 코드:
import pandas as pd
import numpy as np
n_subject = 10 ** 6
pass_rate_pct = 40
all_iter = []
for k in range(8):
k = k + 1
pass_fails = []
for i in range(n_subject):
trial = 0
for j in range(k):
pass_fail = randint(0, 10000) / 10000
if pass_fail < (pass_rate_pct / 100):
pass_fails.append(1)
trial = 1
break
if trial == 0 : pass_fails.append(0)
all_iter.append({'몇 번 시도하는가' : str(int(k)) + ' 회',
'합격할 확률' : str(int(np.mean(pass_fails)*1000) / 10) + ' %'})
pd.DataFrame(all_iter).T'취득한 데이터 사이언스와 직,간접적으로 관련이 있는 자격증 모음' 카테고리의 다른 글
| 빅데이터 분석기사[실기] 후기 (1) | 2021.08.10 |
|---|---|
| 데이터 분석 자격 / 수료증 모음 (0) | 2021.04.18 |
| 데이터 분석 / 데이터 사이언스 자격증 공부의 방향성 (1) | 2021.02.28 |

